Your kid is about to go out to collect some candies. You have learnt how to build, given a set of houses 
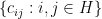
But now you face the following dilemma. You have a teenager kid too whom himself used to collect candies for several years in the past. He knows how much candies each house in the neighborhood is likely to give away from his past experience. So you wonder, may it be possible to exploit your teen kid’s knowledge so as to build tours that are less likely to fill you younger kid’s bag before completion?
The short answer is YES, IT IS POSSIBLE. A longer answer though would require a little more explanation to do. From your teen kid past experience, you may build a probability distribution of the amount of candy that each house is likely to give away to each kid. From the multiple possible probability distributions, you may use a method to calibrate which one fits best the behavior of each particular case. The CVRP instance that we explored in this post should now be seen as a problem in which the amount of candy given away in each house is a random variable.
 But now you face another problem: the amount of candy given away in each house is not known in advance and you should consider (in principle) all the possible outcomes of such random variables. How do you select the best possible decision for the whole set of potential outcomes? The first (and possibly the most intuitive) approach that one would consider is to find a solution for every possible outcome. What if one finds plenty of those solutions? Indeed, not only you have the problem of considering one solution among many, but also you may select one that is good for a single possible outcome and potentially VERY BAD for the rest. This also takes us to the next issue. A solution may be feasible for a given outcome (it respects the bag capacity), but unfeasible for another one (you end up collecting on a tour more candies that you were originally expecting and your bag becomes full before completing it). How should you then compute the cost of a solution? This type of decision is usually referred to as the recourse in the slang of stochastic optimization. A typical recourse consists in getting back home after your kid’s bag becomes full of candies and then retake your tour whenever you left it.
But now you face another problem: the amount of candy given away in each house is not known in advance and you should consider (in principle) all the possible outcomes of such random variables. How do you select the best possible decision for the whole set of potential outcomes? The first (and possibly the most intuitive) approach that one would consider is to find a solution for every possible outcome. What if one finds plenty of those solutions? Indeed, not only you have the problem of considering one solution among many, but also you may select one that is good for a single possible outcome and potentially VERY BAD for the rest. This also takes us to the next issue. A solution may be feasible for a given outcome (it respects the bag capacity), but unfeasible for another one (you end up collecting on a tour more candies that you were originally expecting and your bag becomes full before completing it). How should you then compute the cost of a solution? This type of decision is usually referred to as the recourse in the slang of stochastic optimization. A typical recourse consists in getting back home after your kid’s bag becomes full of candies and then retake your tour whenever you left it.
A good solution in the language of stochastic optimization then is one that is good on average, this is that, when considering the costs + the recourse for every possible outcome of the random variables, becomes minimum in expectancy. In the case of vehicle routing, the problem just described is known in the literature as the vehicle routing problem with stochastic demands and is substantially harder than its deterministic counterpart if the number of possible outcomes is too large. Fortunately for you (and your kid), a number of algorithmic tricks allows for the heuristic solution of real-size problems in moderate computing times.